
 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks

The application that we are going to discuss in this post was running on Elastic Beanstalk (EBS) service in Amazon Web Services (AWS). Intermittently this application was throwing HTTP 502 Bad Gateway error. In this post, lets discuss how we troubleshooted and resolved this HTTP 502 bad gateway error in Elastic Beanstalk service.
AWS Elastic Beanstalk architecture
This application was running on AWS Elastic Load Balancer, Nginx 1.18.0, Java 8, Tomcat 8, Amazon Linux in AWS Elastic BeanStalk service (EBS). For the folks who are not that familiar with EBS, below is its high level architecture.
Fig: AWS Elastic Beanstalk architecture
There is an AWS elastic load balancer in the forefront. This Load Balancer will distribute the traffic to a set of EC2 instances (which can be auto-scaled). Each EC2 instance will have a Nginx web server and a Tomcat application server. Requests sent by the Elastic Load Balancer are first handled by the Nginx server. Then the Nginx server forwards the request to the tomcat server.
HTTP 502 Bad Gateway error
Intermittently (not always), this application was throwing HTTP 502 bad gateway errors. Few seconds later once again service will resume and things will start to function normally. It wasnt clear what was causing this HTTP 502 bad gateway error in the AWS Elastic Beanstalk environment.
We first need to understand what this HTTP 502 bad gateway error means. This error is thrown by a web server/gateway/proxy server when it gets an invalid response from the backend end server to which its talking to.
HTTP 502 thrown by Nginx in AWS EBS
Now the question is: There are three primary components in the EBS stack:
1.Elastic Load Balancer
2.Nginx web server
3.Tomcat Application server
In these 3 components which one is throwing HTTP 502 bad gateway error?
Fig: Screenshot of the HTTP 502 Bad gateway error thrown by Nginx server
Above is the screenshot of the HTTP 502 bad gateway error that we were receiving. There is a clue in this screenshot to indicate who is throwing this HTTP 502 error. If you notice the highlighted part of the screen, you will see this HTTP 502 bad gateway error to be thrown by the Nginx server.
As per the HTTP 502 error definition, Nginx should be throwing this error only if it would have got invalid response from the tomcat server. Thus, this clue helped to narrow down that Tomcat server is the source of the problem.
Out of memory: Kill process or sacrifice child
Inorder to identify the source of the problem, we executed the open source yCrash script on the EC2 instance in which tomcat server was running. yCrash script captures 16 different artifacts from the technology stack, which includes: Garbage Collection log, thread dump, heap dump, ps, top, top -H, vmstat, netstat, .. We uploaded the captured artifacts into the yCrash server for analysis.
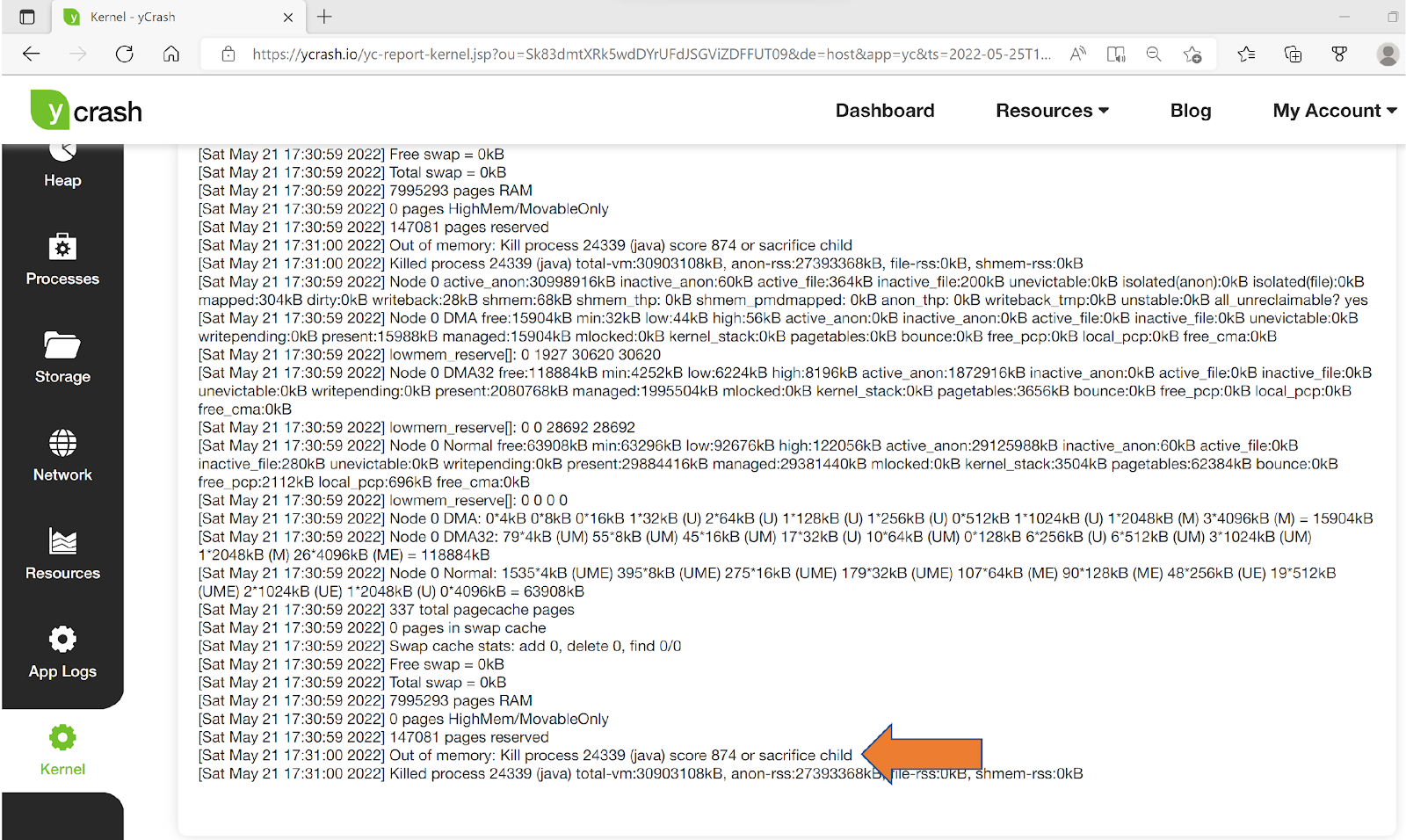
One of the artifacts that yCrash script captures is kernel log file. In this log file all the events that happened in the Linux kernel can be found. yCrash pulls out critical errors and warnings from the log file & presents them. Below is the analysis report of the kernel log generated by the yCrash.
Fig: yCrashs Kernel log analysis reporting Out of memory: kill process or sacrifice child
Please see the highlighted error message in the kernel log:
[Sat May 21 17:31:00 2022] Out of memory: Kill process 24339 (java) score 874 or sacrifice child
It indicates that the Tomcat server which is a Java process was terminated. Linux kernel will terminate processes if their memory consumption exceeds the devices RAM capacity limit. This is the exact scenario happening in this application as well. Whenever the applications memory consumption goes beyond the capacity limits, the Linux kernel was terminating the tomcat server.
Root cause Lack of RAM
Now the question is: How Linux terminating tomcat server can result in intermittent HTTP 502 bad gateway error? Shouldnt a complete outage need to happen? Its a fair question.
If you recall, this application is running on AWS Elastic Beanstalk (EBS) service. EBS service will automatically restart the tomcat server whenever it gets terminated. Thus its hilarious. Linux is terminating and EBS is restarting the tomcat server. During this intermittent period, customers were experiencing HTTP 502 bad gateway errors.
Solution Upgrading EC2 instance RAM capacity
Apparently, the application was running on EC2 instances which had only 1GB RAM capacity. It wasnt sufficient memory to run tomcat server, Nginx server and other kernel processes. Thus, when the application was upgraded to run on 2GB RAM capacity EC2 instance, the problem got resolved.
Note: Here is a similar problem faced by another application which was running in an non-AWS environment. It might be an interesting read as well.
https://youtu.be/XyOP8LGT2zA




 Reply With Quote
Reply With Quote